PCIe的历史
PCIe是在PCI(Peripheral Component Interconnect)的基础上发展而来的。而PCI则是Intel在1992年提出的一套总线协议,并召集其它的小伙伴组成了名为 PCI-SIG (PCI Special Interest Group)(PCI 特殊兴趣组)的企业联盟。 这个组织就负责PCI和其继承者们(PCI-X和PCIe的标准制定和推广)。
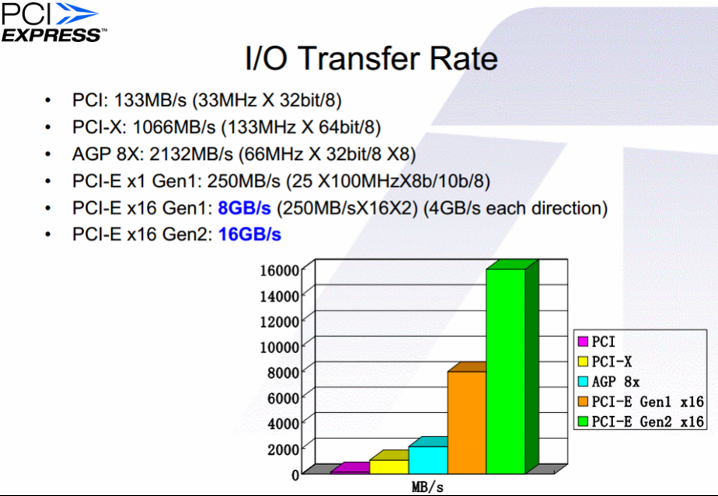 PCI的提出是为了解决当时的ISA/EISA,MCA,VLB等总线速度太慢,接口混乱不统一而提出的,因为它的统一和开放,PCI获得了厂商的欢迎和支持,各种PCI设备应运而生丰富了PC的生态。虽然PCI总线获得了巨大的成功,但是随着CPU主频的不断提高,PCI总线的带宽越来越难以满足要求。PCI总线不断的升级从32位/33MHz扩展到64位/64MHz,PCI-X甚至提升到了533MHz,最大理论带宽为4263MB。但是仍然无法解决其体系结构中存在的一些先天不足:
PCI的提出是为了解决当时的ISA/EISA,MCA,VLB等总线速度太慢,接口混乱不统一而提出的,因为它的统一和开放,PCI获得了厂商的欢迎和支持,各种PCI设备应运而生丰富了PC的生态。虽然PCI总线获得了巨大的成功,但是随着CPU主频的不断提高,PCI总线的带宽越来越难以满足要求。PCI总线不断的升级从32位/33MHz扩展到64位/64MHz,PCI-X甚至提升到了533MHz,最大理论带宽为4263MB。但是仍然无法解决其体系结构中存在的一些先天不足:
-
PCI是共享总线,总线上的所有设备必须共享带宽,另外总线协议还有一些开销,虽然64位/64MHz理论上可以提供最大带宽为532MB,但是实际可以利用的数据带宽远低于峰值。
-
PCI总线是并行的,它通过提高总线频率和位宽的方式增加传输带宽,但是这种方式的性价比比较低,因为位宽的增加需要更多的芯片管脚,从而导致64位的芯片价格远高于32位,另外在主板设计的时候也需要更多层的PCB实现64位芯片接口,增加成本和布线 难度;而且因为频率和位宽的增加带来了信号完整性的问题,也影响了总线的负载能力。比如33MHz的总线可以驱动10个负载,66MHz的总线最多只能渡情4个负载。
-
PCI总线并没有考虑服务质量QoS,因为PCI总线是并行的主从式的总线,总线上的设备只能轮流使用PCI总线,当一个设备长期占用总线时将阻止其他设备对总线的使用但是有些实时的设备如数据采集卡,音频或者视频的应用需要额定的带宽,因此就没法得0以 满足。
PCIe如何解决PCI体系结构存在的问题的呢?
-
PCIe使用了高速差分总线端到端的连接方式替代并行总线,与并行总线相比高速差分信号可以使用更高的时钟频率,而且更少的信号线实现之前需要更多的芯片管脚才能实现的总线带宽,而且与单端信号相比差分信号的抗干扰能力更强。
-
PCIe使用了网络通信中使用的技术如基于多种数据路由方式,报文数据传送,以及Traffic class和virtual channel结束数据传输过程中的QoS问题。
-
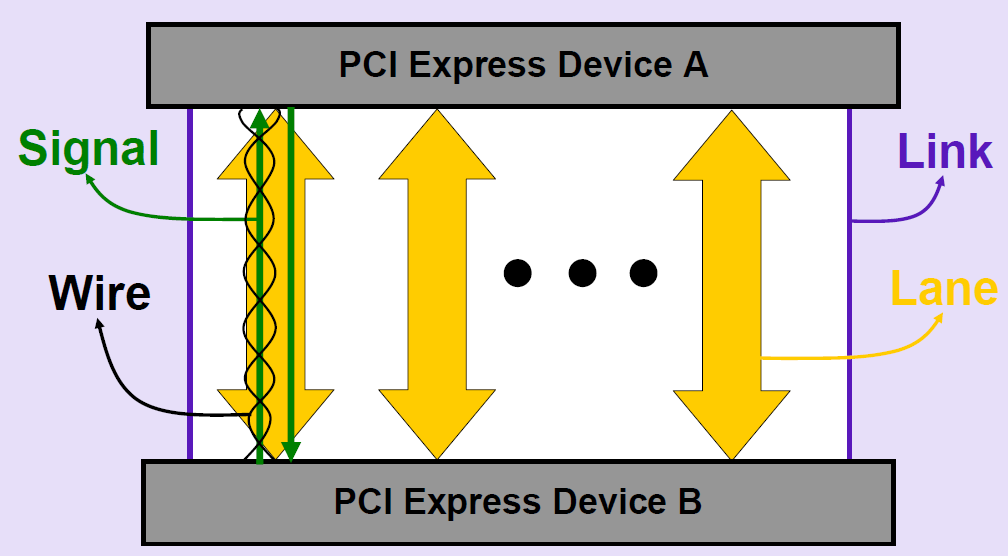
PCIe的链路可以由多条Lane组成,换句话来说它的性能可扩展。可以像搭积木一样增加Lane或者减少Lane的组合来提高性能。
-
PCIe总线在系统软件编程上和PCI总线兼容,绝大多数的PCI总线事务都被PCIe总线保留,PCI设备的配置空间也被PCIe继承。
PCIe总线基础
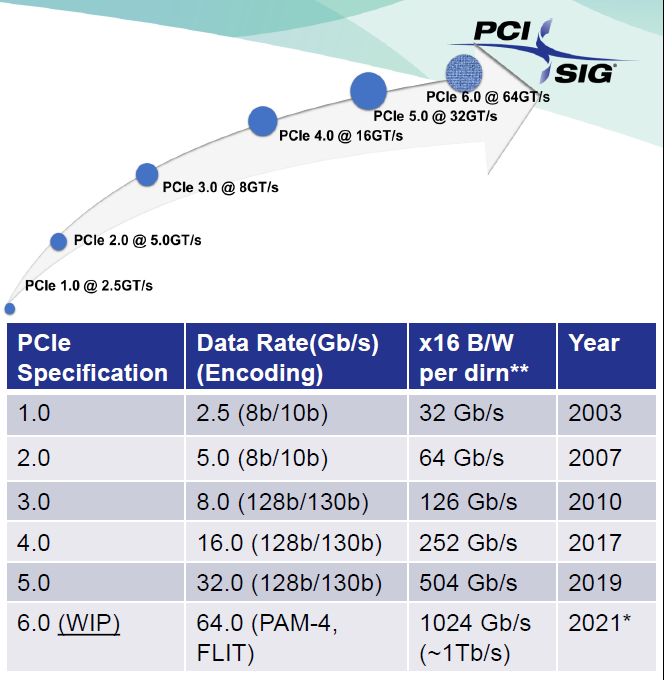
PCIe 从2003年的1.0版本开始到现在的6.0经历了数次更新,速度从2.5GT/s提升到了65GT/s。
 PCIe采用了端到端的全双工的传输设计,基于数据包的传输,设备之间通过link相连,link支持1到32个通道(lane)。
PCIe采用了端到端的全双工的传输设计,基于数据包的传输,设备之间通过link相连,link支持1到32个通道(lane)。
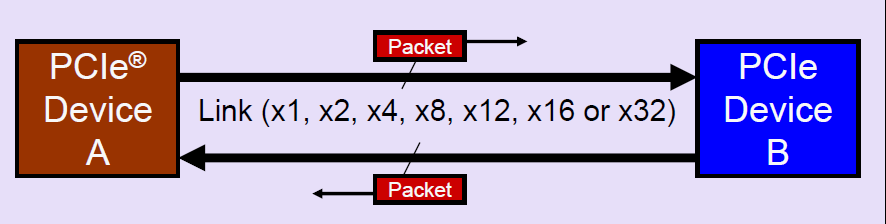
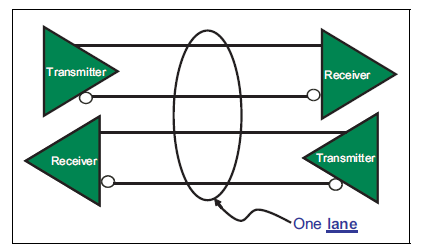 每个链路可以包含多达32个通道。
每个链路可以包含多达32个通道。
 PCIe 采用了差分信号对数据进行收发,以提高总线的性能 。
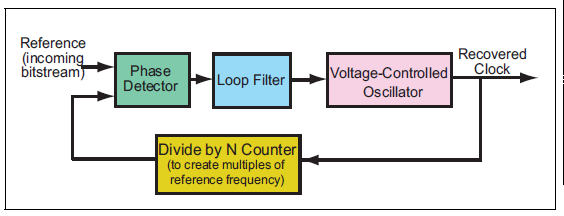
除了差分总线,PCIe还引入了嵌入式时钟的技术(Embedded Clock),即发送端不再向接收端发送时钟,但是接收端可以通过8b/10b,128b/130b的编码从数据Lane中恢复出时钟。
PCIe 采用了差分信号对数据进行收发,以提高总线的性能 。
除了差分总线,PCIe还引入了嵌入式时钟的技术(Embedded Clock),即发送端不再向接收端发送时钟,但是接收端可以通过8b/10b,128b/130b的编码从数据Lane中恢复出时钟。
PCIe总线的层次结构
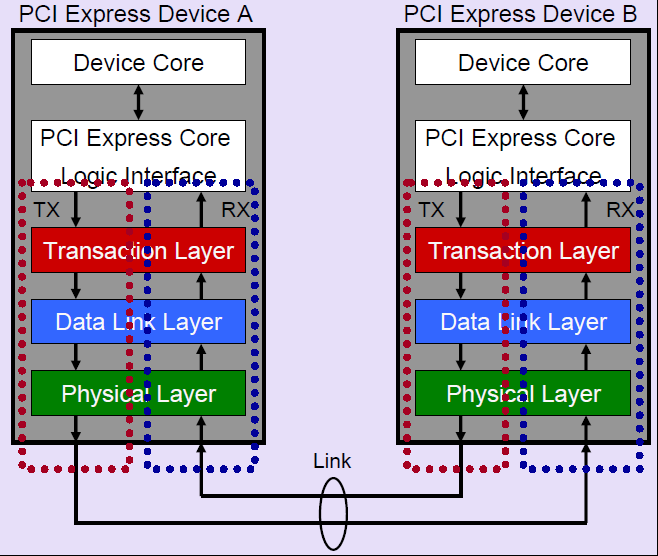
PCIe使用串行的基于数据包的传输方式,这种方式有效的去除了PCI总线中存在的一些sideband信号如INT#,PME#。 PCIe总线是分层实现的,它包含多个层次,从上到下分别是应用层(也就是下图中的Device Core,PCIe Core HW/SW Interface),事务层(Transaction Layer),数据链路层(Data Link Layer),物理层(Physical Layer),其中,应用层并不是PCIe Spec所规定的内容,完全由用户根据自己的需求进行设计,另外三层都是PCIe Spec明确规范的,并要求设计者严格遵循的。PCIe的层次结构有点类似TCP/IP的协议实现,不过PCIe的各个层次都是通过硬件逻辑实现的。发送时数据报文先由应用层产生,然后经过事务层,数据链路层和物理层最终发送出去。接收端则是相反的一个步骤,数据先经过物理层,然后向上送给数据链路层,事务层,最后到达应用层。
-
事务层
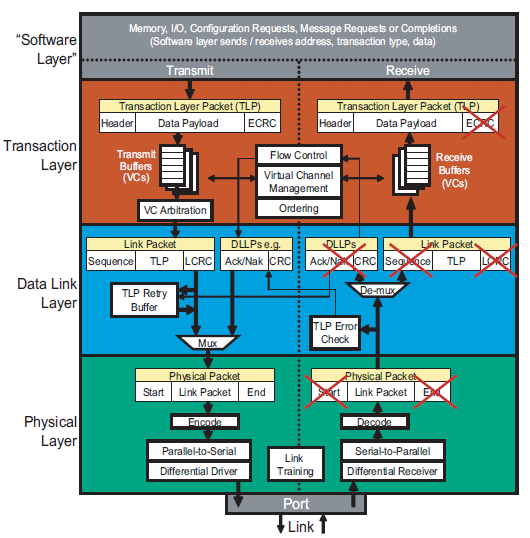
PCIe事务层定义了总线所使用的事务,其中大部分都与PCI总线兼容在PCIe Spec中,规定了四种类型的请求(Request):Memory、IO、Configuration和Messages。其中,前三种都是从PCI/PCI-X总线中继承过来的,第四种Messages是PCIe新增加的类型。事务层接收来自核心层的数据并将其封装成TLP(Transaction Layer Packet)发向数据链路层。另外事务层也可以从数据链路层接收数据报文,然后转发到核心层。
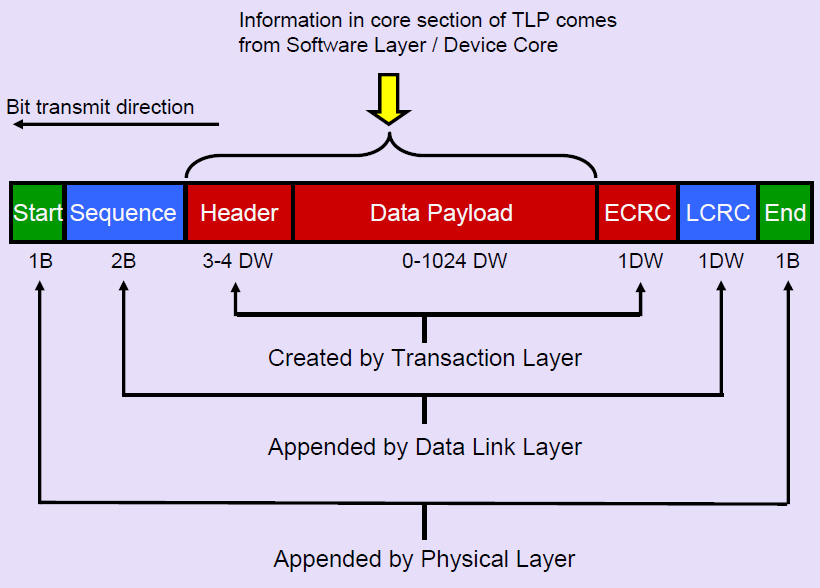
-
数据链路层
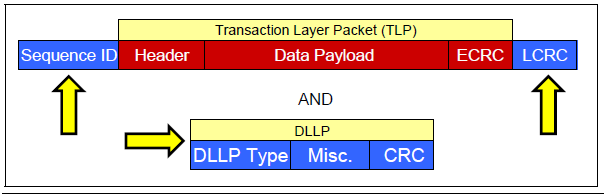
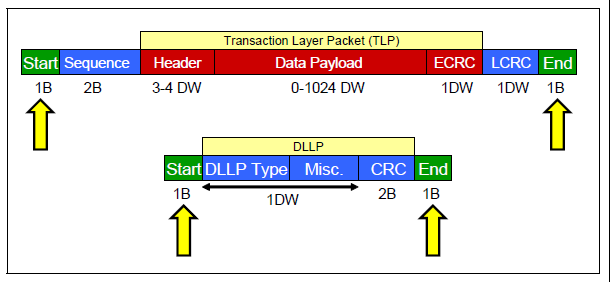
数据链路层接收来自事务层的数据报文,添加Sequence Number前缀和CRC后缀。数据链路层使用ACK/NAK协议保证报文的可靠传递。另外它还定义了多种DLLP(Data Link Layer Pakcet),DLLP 产生于数据链路层结束于数据链路层。DLLP于TLP并不相同,DLLP不是TLP加上Sequence Number和CRC后缀组成的。
-
物理层
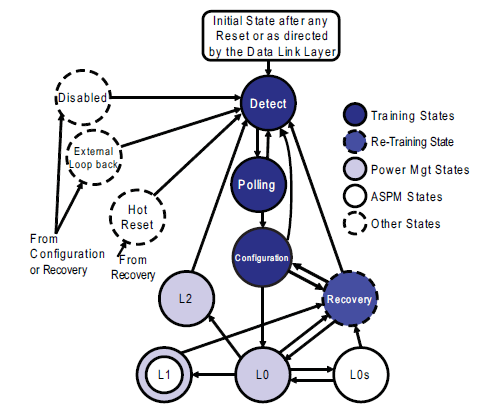
物理层是PCIe总线的最底层,将PCIe设备相互连接在一起。它负责接收和转发各种数据包(TLP,DLLP)。另外它还创建和解码一些专门的序列Ordered-Set Packet或者叫做PLP(Physical Layer Packet),这些序列用于同步和管理链路。物理层还实现了链路训练和初始化的功能,它通过LTSSM来完成(Link Training and Status State Machine)。

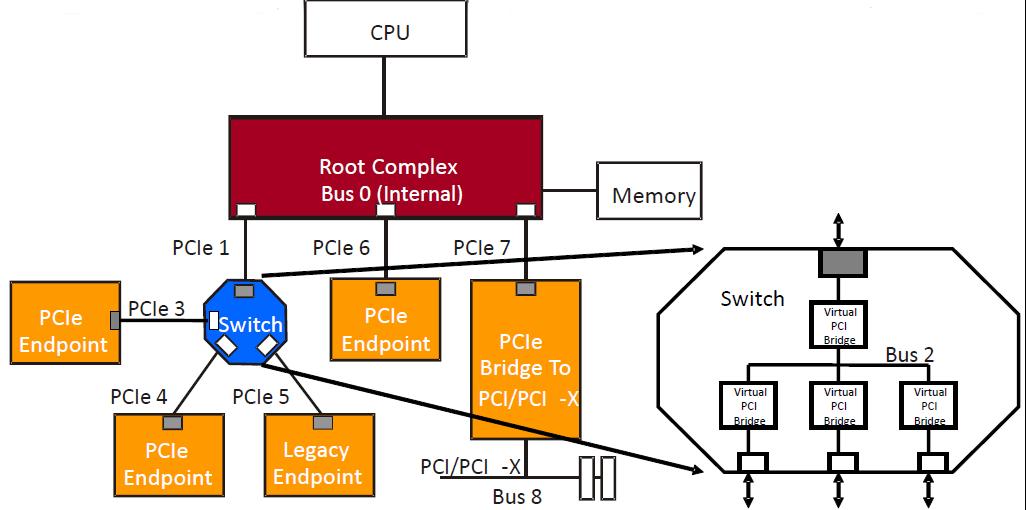
PCIe体系的拓扑结构
PCIe作为局部总线主要是用来处理器系统中的外部设备,当然它也可以用来连接其他的处理器系统。在大多数处理器系统中都使用了RC,Switch和PCIe-PCI桥等模块用来连接PCIe和PCI设备。
-
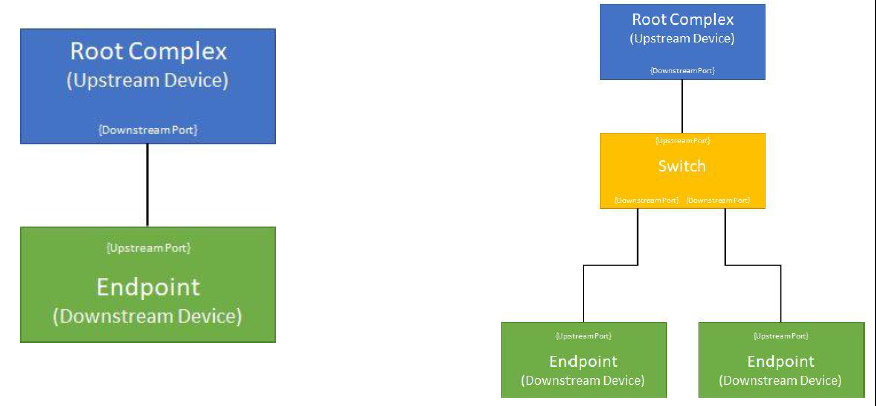
Up/Down Stream Port
PCIe spec规定可以与RC直接或者间接相连的端口称之为上游端口,在PCIe总线中,RC的位置一般在上方,这也是上游端口的由来。除上游端口之外的其它端口就是下游端口。
-
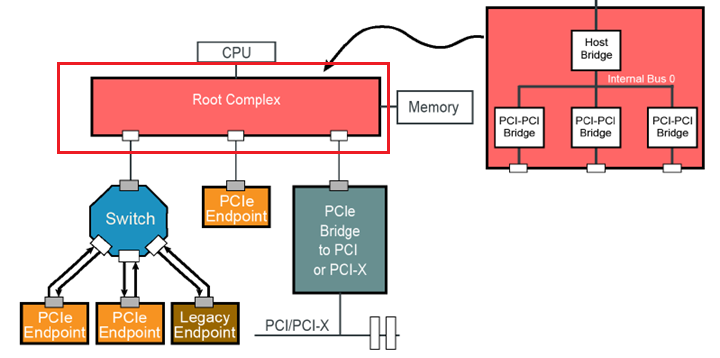
Root Complex
RC是PCIe体系结构中的一个重要的组成部件,它与PCI总线的中Host bridge有些类似,是CPU和PCIe总线直接的接口。它的主要功能是完成存储器域到PCIe总线域的地址转换,随着虚拟化技术的引入,RC的功能也越来越复杂。RC把来自CPU的request转化成PCIe的4种不同的requests(configuration, Memory, I/O, Message)并发送给接在它下面的设备。从软件的角度来看,RC像是一组虚拟的PCI-PCI桥。
-
PCIe Switch & Bridge
Switch提供了分散或者是聚合的功能,它允许更多的设备接入到 一个PCIe Port。它扮演了数据包路由的功能。Bridge提供了一个转换接口用来连接其他的总线,如PCI/PCI-X。这样可以允许在PCIe的系统中接入一张旧的PCI设备。
-
PCIe Endpoint
它只有一个上游端口,位于PCIe拓扑结构的树的末端。它作为请求的发起者或者完成者。分为Legacy Endpoint和Native Endpoint,Legacy使用PCI总线的操作用于支持向后兼容。
PCIe的软件编程接口
-
PCIe 配置空间
PCI spec规定了256字节的配置空间,PCIe总线为了兼容PCI设备,几乎完整的保留了PCI总线的配置空间。并将配置空间扩展到了4KB,用于支持一些PCIe总线中的新功能,如Capability,power management, MSI等。
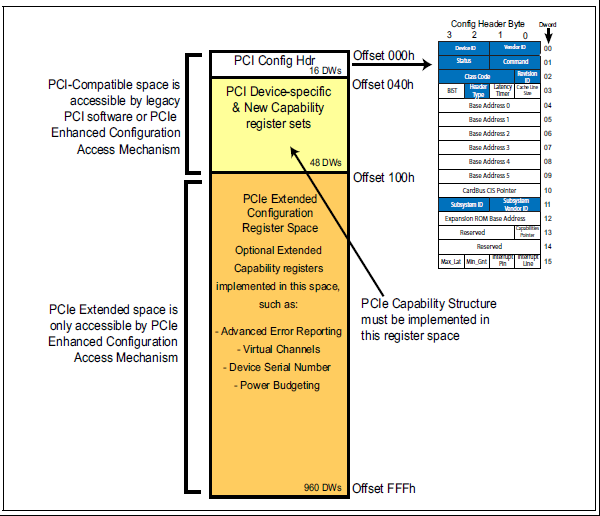 PCI设备使用Bus Device Function用来区分不同的设备(简称BDF),PCIe也继承了这种编码方式,另外PCI定了以了两种header的格式(配置空间内容不一致),一种是PCI device,另一种是Bridge,同样PCIe也继承了这种格式。
PCI设备使用Bus Device Function用来区分不同的设备(简称BDF),PCIe也继承了这种编码方式,另外PCI定了以了两种header的格式(配置空间内容不一致),一种是PCI device,另一种是Bridge,同样PCIe也继承了这种格式。
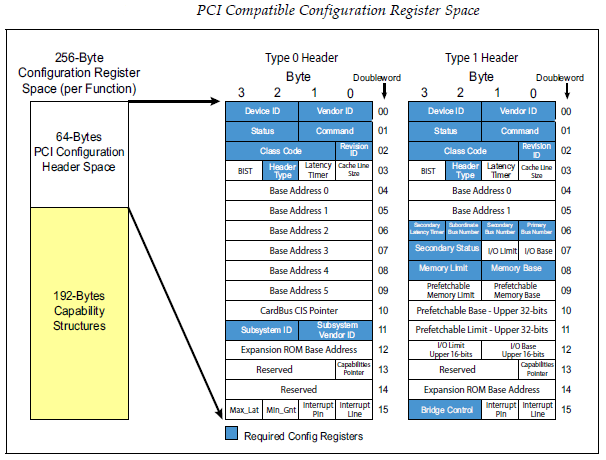 PCI设备使用IO空间的CF8(Configuration Address Port)/CFC(Configuration Data Port)地址来访问配置空间。
PCI设备使用IO空间的CF8(Configuration Address Port)/CFC(Configuration Data Port)地址来访问配置空间。
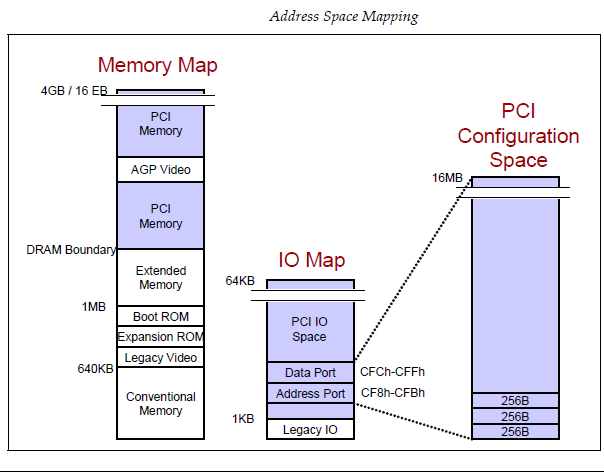
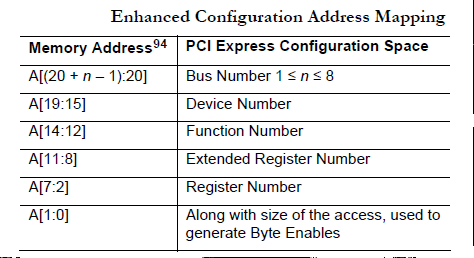
 PCIe将配置空间扩展到4KB,原来CF8/CFC的访问方式仍然可以访问所有PCIe配置空间的前256Byte,但是访问不了剩下的空间。所以PCIe引入了所谓的增强配置空间访问机制Enhanced Configuration Access Mechanism,它通过将配置空间映射到MMIO空间,使得对配置空间的访问就像对内存一样,也因此可以访问完整的4KB配置空间。
PCIe将配置空间扩展到4KB,原来CF8/CFC的访问方式仍然可以访问所有PCIe配置空间的前256Byte,但是访问不了剩下的空间。所以PCIe引入了所谓的增强配置空间访问机制Enhanced Configuration Access Mechanism,它通过将配置空间映射到MMIO空间,使得对配置空间的访问就像对内存一样,也因此可以访问完整的4KB配置空间。
-
PCIe的枚举
PCI枚举的过程其实是一个使用深度优先的算法不断递归发现新设备的过程,以下图为例主要包含以下步骤。
-
从RC开始,寻找设备和桥,发现桥以后设置下一级Bus,继续递归发现下一级PCI设备子树。
-
先从Bridge A开始,尝试读取配置空间的Vendor ID,看看设备是否存在而且只是有一个Function。如果不存在就继续尝试Device1-31 Function 0。
-
下图的情况A的header type是01h表明这是一个Bridge,Multifunction Bit7是0表示这是一个single function.
-
设置Bridge A 的 Primary Bus Number Register = 0 Secondary Bus Number Register = 1 Subordinate Bus Number Register = 255。这样接在这个bridge下面的总线是bus1,最大的总线是255。
-
继续深度优先搜索,在探索bus0上的其它设备之前,我们先要去探索bus1上的设备树。
-
读取B1D0F0 Vendor ID和Header Type也就是下图的C,我们同样也能知道它是一个Bridge而且是单功能的。
-
设置Bridge C的配置空间Primary Bus Number Register = 1 Secondary Bus Number Register = 2 Subordinate Bus Number Register = 255。
-
尝试读取B2D0F0的Vendor ID也就是下图的D,同样我们可以知道它是一个单功能的桥设备。
-
设置D的配置空间的寄存器Primary Bus Number Register = 2 Secondary Bus Number Register = 2 Subordinate Bus Number Register = 255。
-
读取B3D0F0的Vendor Id和Header Type进而确认 它是一个设备而且是多Function。
-
尝试遍历所有的8个Function,可以发现一共存在2个Function 而且都是Endpoint。
-
继续尝试遍历bus3下面的所有的Device1-31,这次应该没有发现任何其他的Function。
-
更新Bridge D真正的Subordinate Bus Number Register = 3,然后回到上一级(bus2)继续遍历虚招有效的Function,在下图的例子中我们会找到Bridge E B2D1F0。
-
同样读取Vendor ID和Header Type表面 E是一个单功能的桥设备。
-
设置E的 Primary Bus Number Register = 2 Secondary Bus Number Register = 4 Subordinate Bus Number Register = 255。
-
继续深度优先遍历读取B4D0F0的Vendor ID以及Header Type,表明它是一个单功能的设备。
-
尝试遍历bus4 device 1-31,下图中找不到其他的功能设备。
-
这时已经到了树的底部,接下来更新上层Bridge E的Subordinate Bus Number Register = 4。然后回到上一级总线bus2,尝试读取device2-31,因为下图没有实现,所以在bus2上找不到其他的设备。
-
更新上一级总线也就是C的真正的Subordinate Bus Number Register = 4,然后尝试读取Device1-31的其它Function,因为没有实现,所以找不到其它的Function。
-
继续向上更新bus1的上一级Bridge也就是A,它的真正的Subordinate Bus Number Register = 4,回朔到上一级总线Bus0,继续读取下一个设备B0D1F0(也就是B)的Vendor ID和Header Type,接下来的就是重复A的过程。
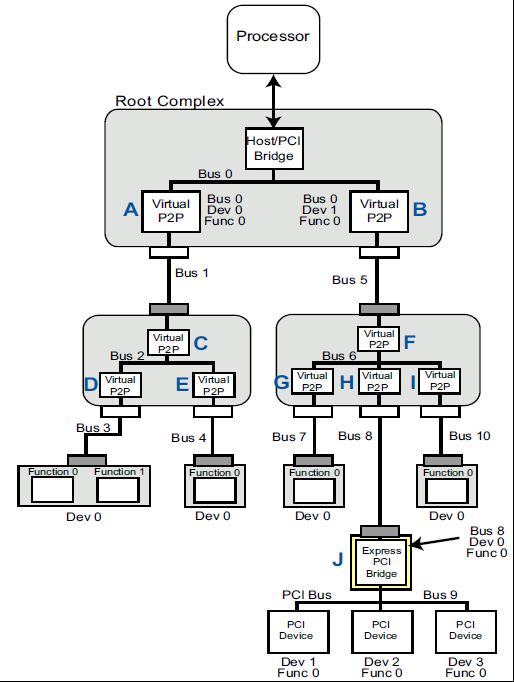 除了配置bus,枚举过程中还会通过读取bar记录所有MMIO和IO的需求情况,然后设置对应的bar以及必要的Capabilities。
除了配置bus,枚举过程中还会通过读取bar记录所有MMIO和IO的需求情况,然后设置对应的bar以及必要的Capabilities。 -
Refer: