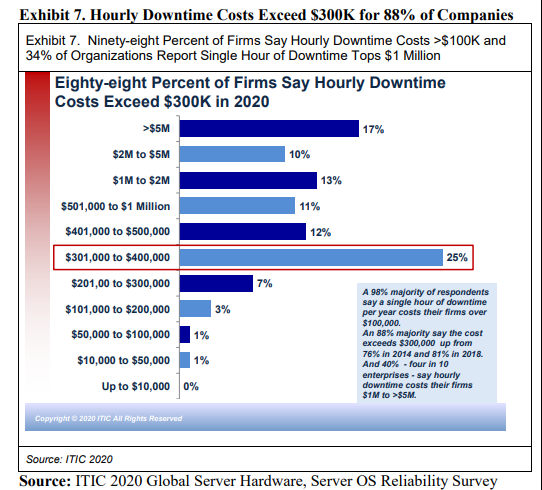
RAS 这个术语最初来自于IBM的大型机,早期是高大上的存在,这些年随着x86服务器的发展和进步,x86支持越来越多的RAS Feature占据了越来越多的市场份额。RAS的全称为 Reliability, Availability,Serviceability。Reliability(可靠性)指的是系统必须尽可能的可靠,不会意外的崩溃,重启甚至导致系统物理损坏,这意味着一个具有可靠性的系统必须能够对于某些小的错误能够做到自修复,对于无法自修复的错误也尽可能进行隔离,保障系统其余部分正常运转。Availability(可用性)指的是系统必须能够确保尽可能长时间工作而不下线,即使系统出现一些小的问题也不会影响整个系统的正常运行,在某些情况下甚至可以进行 Hot Plug 的操作,替换有问题的组件,从而严格的确保系统的宕机时间在一定范围内。Serviceability 指的是系统能够提供便利的诊断功能,如系统日志,动态检测等手段方便管理人员进行系统诊断和维护操作,从而及早的发现错误并且修复错误。RAS 作为一个整体,其作用在于确保整个系统尽可能长期可靠的运行而不下线,并且具备足够强大的容错机制。这对于像大型的数据中心,网络中心如股票证券交易所,电信机房,银行的数据库中心等应用环境是不可或缺的一部分。调研机构经过行业调查发现,不同的行业的关键业务中断会带来巨额的经济损失,下图是最新一期的调研报告,88%的企业每小时的服务器宕机会带来超过30万刀的损失,由此可见RAS的重要性以及对于可靠性需求的增长非常迅速。
RAS 主要处理的有CPU上的错误;内存上的错误,IO/PCIe上的错误,芯片组的错误以及平台硬件的错误。
Memory RAS:
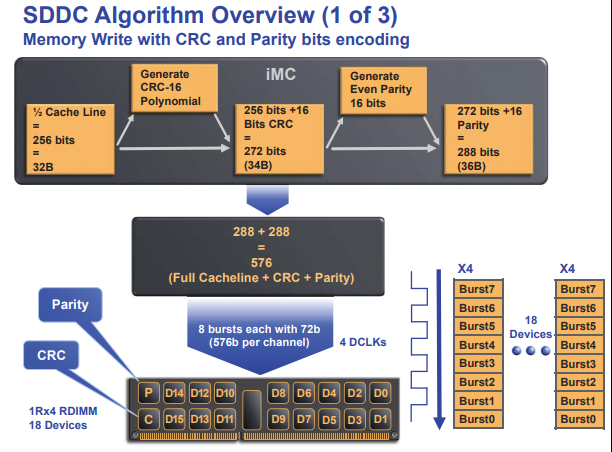
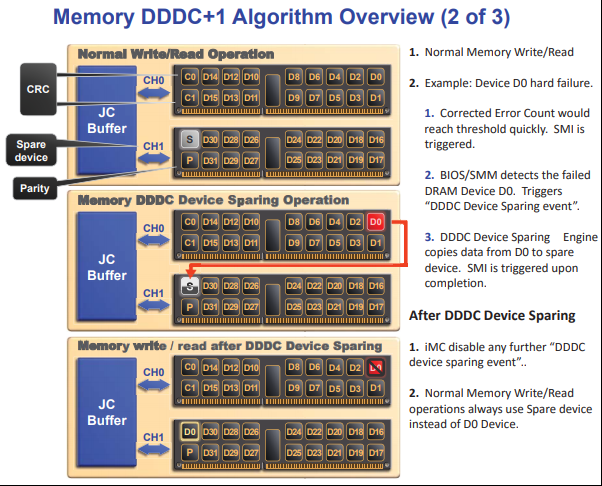
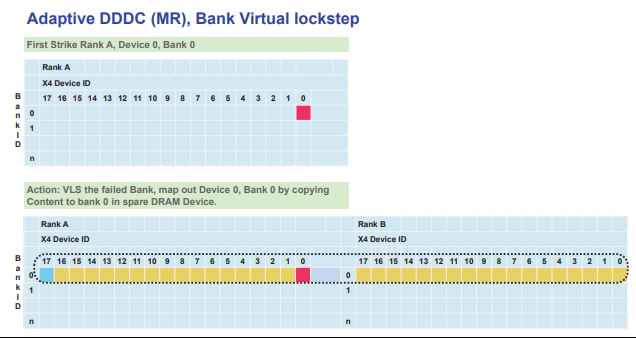
从重要性上看内存的RAS特性是最为重要的,Google的一份调查报告显示内存错误率其实比想象中的要高“人们首次发现内存错误普遍存在.所有在用设备中大约1/3每年至少遇到一次内存错误,平均每年发生的可修正错误为22000次.在不同平台上得出的数据不同,有些平台大约有50%的设备受到可修正错误的影响,有的仅为12%~27%。”而服务器的程序都是跑在内存中的,如果因为内存出错没有被修复那就会导致程序的崩溃进而带来严重的损失。而且内存的频率越来越高,颗粒的密度也越来越大,容量也越来越大,自然出问题的概率也是越来越大,内存故障已经成为数据中心最严重的问题之一。内存RAS特性主要包含 Single Device Data Correction (SDDC),Double Device Data Correction (DDDC),Adaptive Double DRAM Device Correction (ADDDC) 。这些Feature都是以ECC 为基础逐步扩展出来的。
CPU RAS:
CPU RAS 也非常关键。X86 处理器将原本属于RISC架构专属的诸如机器校验架构(Machine Check Architecture,MCA)等特性移植了过来。当我们提到CPU RAS主要是指MCA 的机制。Intel从奔腾4开始的CPU中增加了一种机制,称为MCA——Machine Check Architecture,它用来检测硬件(这里的Machine表示的就是硬件)错误,比如系统总线错误、ECC错误等等。这套系统通过一定数量的MSR(Model Specific Register)来实现,这些MSR分为两个部分,一部分用来进行设置,另一部分用来描述发生的硬件错误。当CPU检测到不可纠正的MCE(Machine Check Error)时,就会触发Machine Check Exception,通常软件会注册相关的函数来处理这个exception,在这个函数中会通过读取MSR来收集MCE的错误信息,然后重启系统。当然由于发生的MCE可能是非常致命的,CPU直接重启了,没有办法完成MCE处理函数;甚至有可能在MCE处理函数中又触发了不可纠正的MCE,也会导致系统直接重启。当然CPU还会检测到可纠正的MCE,当可纠正的MCE数量超过一定的阈值时,会触发CMCI(Corrected Machine Check Error Interrupt),此时软件可以捕捉到该中断并进行相应的处理。CMCI是在MCA之后才加入的,算是对MCA的一个增强,在此之前软件只能通过轮询可纠正MCE相关的MSR才能实现相关的操作。MCA以bank为单位对错误进行处理,全局相关的寄存器组定义了如何开启 MCA 的能力。每一个 BANK 则具体对应一类错误源,如 CPU,MEMORY,CACHE,CHIPSET 等等。每一个 BANK 都可以进行单独的控制,这样软件就能够针对每一个 BANK 使用特定的方式进行处理。由于 MCA 以时间窗口为单位对错误进行采样,因此在每一个采样结束时有可能会发现有不止一个的错误产生,但是只会触发一次中断或者异常,因此当软件进行处理时必要要轮询所有的 BANK 以确保每一个产生的错误都可以被处理。
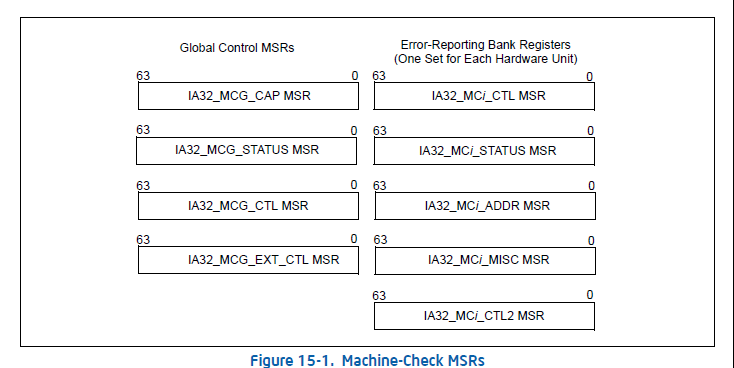
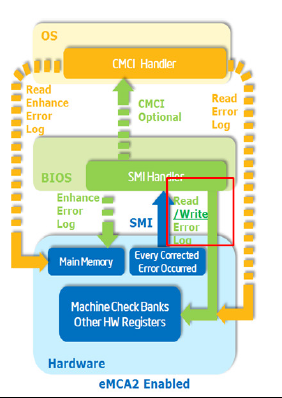
Intel在MCA的基础上又推出了EMCA,简单来讲它可以将MCE和CMCI转换成SMI,让Firmware(BIOS)可以先行处理,然后再丢给OS。AMD也有类似的机制,只是不叫EMCA。
IO/PCIe RAS:
PCI定义两个边带信号PERR#和SERR#来处理总线错误,其中PERR#主要对应的是普通数据奇偶校检错误,而SERR#主要对应的是系统错误。PCIe取消了PCI总线中的这两个边带信号,采用错误消息的方式来实现错误报告。 PCIe Spec定义了两个错误报告等级。第一个为基本的是所有PCIe设备都需要支持的功能。第二个是可选的,称之为高级错误报告(Advanced Error Reporting Capability)。AER有一组专门的寄存器可以提供更多,更详细的错误信息供软件定位错误和分析原因。
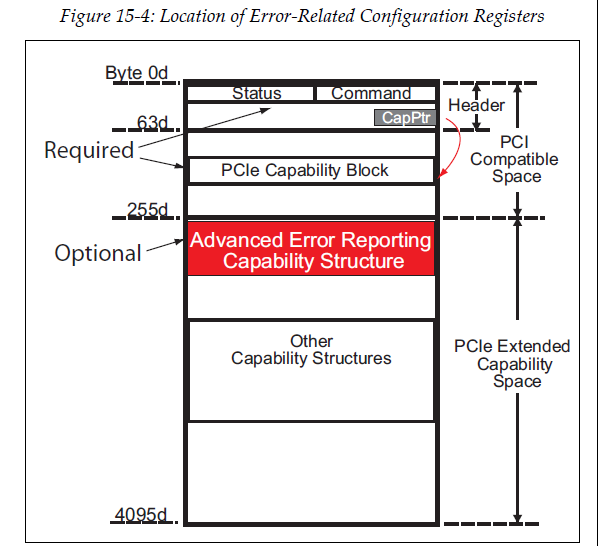
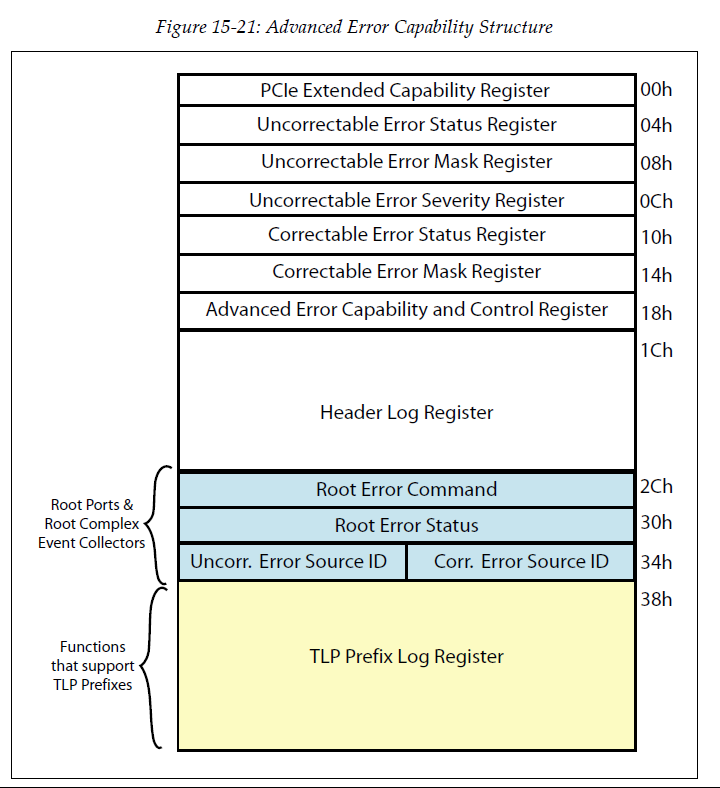
参考:
-
Memory_RAS_Configuration_User_Guide: https://www.supermicro.org.cn/manuals/other/Memory_RAS_Configuration_User_Guide.pdf
-
emca2-integration-validation-guide: https://software.intel.com/content/dam/develop/external/us/en/documents/emca2-integration-validation-guide-556978.pdf
-
服务器RAS性能: https://www.cnblogs.com/quenby/p/5045865.html
-
RAS 在 x86 上的应用及 Linux 实现: https://www.ibm.com/developerworks/cn/linux/l-cn-ras/index.html
-
服务器的黑科技:服务器是怎么做到每年只停机30秒的?: https://zhuanlan.zhihu.com/p/55260207
-
《PCI Express Technology》