MCA 简介
正如我们在RAS简介中提到的,CPU RAS主要是指MCA 的机制。 MCA最初是RISC专属的,X86 处理器将原本属于RISC架构专属的诸如机器校验架构(Machine Check Architecture,MCA)等特性移植了过来。Intel从奔腾4开始的CPU中增加了一种机制,称为MCA——Machine Check Architecture,它用来检测硬件(这里的Machine表示的就是硬件)错误,比如内存的ECC错误,Cache的错误,系统总线错误,奇偶校验错误等。 这些错误对系统的稳定性危害极大而且无法恢复,通常会触发系统的复位操作,然而这些错误在一个大型的服务器环境如服务器集群或者是云计算的环境下是不可避免的,因此必须对此有相应的处理机制。MCA是一个跟随着新处理器的发布不断增加新的特性和增强功能而不断进化的技术。随着SOC集成度越来越高,更多的内存,快速的IO设备被集成进处理器志宏,MCA所能够支持的错误种类也越来越多样和广泛。
MCE的产生通常是由于以下几个原因,1. 违反了主板设计指南,例如因为布线导致信号的干扰和完整性问题。2.处理器工作在非正常的状态,比如超频等进而导致处理器出现意料之外的行为。3.环境因素,比如环境太热,太冷,潮湿或者有辐射。4.风扇或者散热器安装的有问题导致过热。5.没有及时的升级micorode,导致有些fix没有集成进来。6.BIOS或者OS的配置有问题导致MCE的异常处理没有很好的工作。7.板子上的设备如果外插卡,内存条等有问题也可能会导致MCE。
在 MCA 架构的出现之前,OS 对 MCE 的处理非常有限,经常就是简单的重启系统,对于管理员而言,简单的系统重启难以接受,而且出错现场经常无法保存,从而无法排错。即使能够保留下一些日志,除非有很强的专业知识,否则完全不知道真正产生错误的原因是什么。这些问题都在新的 MCA 中得到了解决和改进。利用新的 MCA 架构,CPU可以按照配置产生MCE(machine check exceptions)。对于可以修正的(Correctable)MCE,硬件可以自动从错误状态中恢复,而且并不需要重启系统,早期的可修正的MCE并不需要产生中断,从 45nm Intel 64 处理器(CPUID 06H_1AH)开始引入了corrected machine check error interrupt(CMCI)的机制,用户通过配置相应的model-specific registers (MSR)允许可修正的MCE也会产生中断,软件可以捕捉到该中断并进行相应的处理。对于不可修正的(uncorrectable)MCE,这时系统已经处于不再安全和可以信赖的操作模式,系统必须重启才能恢复。软件可以根据不同的错误源产生的错误类别,错误的严重程度,软件可以选择隔离错误,记录错误,甚至屏蔽错误源(对于不重要的非致命的错误类型)以避免干扰,或是必须要复位系统。在新的 MCA 架构下,错误的记录管理,以及可读性都有了很大的提高。他可以帮助CPU设计人员和CPU调试人员诊断,隔离和了解处理器故障。 帮助系统管理员检测在服务器长期运行期间遭受的短暂故障和与老化有关的故障。MCA恢复功能是基于intel 至强可扩展系列处理器的服务器的容错功能的一部分。 这些功能使系统在检测到未纠正的错误时可以继续运行。 如果没有这些功能,则系统将崩溃,并且可能需要更换硬件或重新引导系统。
MCA 的组成元素
MCA是通过一系列的MSR (Model-Specific Register),来实现MCA的控制与记录。这些MSR整体上分为两个部分如下图所示,其中左边是全局寄存器,右边的5个寄存器为一组被称为1个Bank,它是按照CPU的内部的硬件单元分组,每组成为一个Bank。其中的i表示的每个Bank的Index。
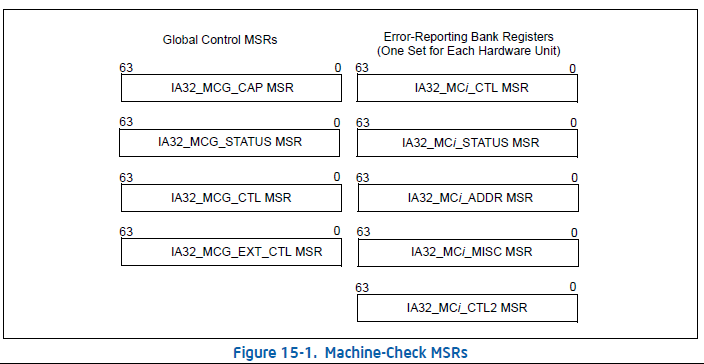
MCA全局控制寄存器
-
IA32_MCG_CAP 是一个只读的MSR,它提供了当前CPU MCA的一些信息,
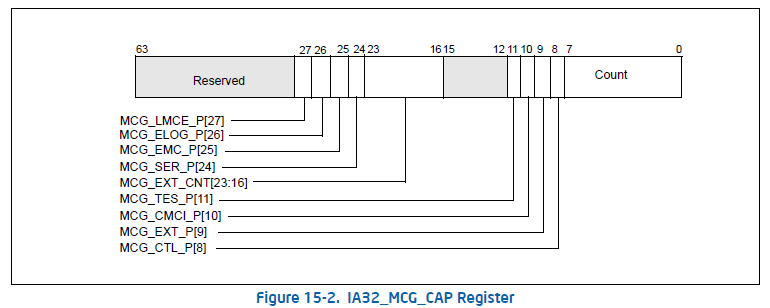
BIT0-7:表示的是CPU支持的Bank的个数。
BIT8:1表示IA32_MCG_CTL有效,如果是0的话表示无效,读取该IA32_MCG_CTL这个MSR可能发生Exception。
BIT9:1表示IA32_MCG_EXT_CTL有效,反之无效,这个与BIT8的作用类似。
BIT10:1表示支持CMCI,但是CMCI是否能用还需要通过IA32_MCi_CTL2这个MSR的BIT30来使能。
BIT11:1表示IA32_MCi_STATUS这个MSR的BIT56-55是保留的,BIT54-53是用来上报Threshold-based Error状态的。
BIT16-23:表示存在的Extended Machine Check Status 寄存器的个数。
BIT24:1表示CPU支持Software Error Recovery。
BIT25:1表示CPU支持增强版的MCA。
BIT26:1表示支持更多的错误记录(需要UEFI、ACPI的支持)。
BIT27:1表示支持Local Machine Check Exception。
-
IA32_MCG_STATUS MSR描述了MCE发生时CPU的状态
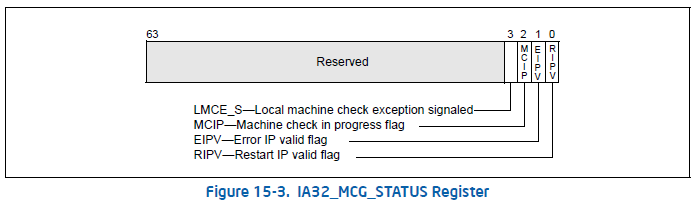
Bit 0: Restart IP Valid. 表示程序的执行是否可以在被异常中断的指令处重新开始。
Bit 1: Error IP Valid. 表示被中断的指令是否与MCE错误直接相关。
Bit 2: Machine Check In Progress. 表示 machine check 正在进行中。
bit 3: 设置后说明生成本地machine-check exception. 这表示当前的机器检查事件仅传递给此逻辑处理器。
-
IA32_MCG_CTL MSR它的存在依赖于IA32_MCG_CAP这个MSR的BIT8。主要用来Disable(写1)或者Enable(写全0)MCA功能。
-
IA32_MCG_EXT_CTL MSR 当IA32_MCG_CAP MSR的MCG_LMCE_P寄存器位被设置时,则IA32_MCG_EXT_CTL MSR可以使用。IA32_MCG_EXT_CTL.LMCE_EN (bit 0) 允许处理器发送MCE信号给系统只的一个逻辑处理器。如果在IA32_MCG_CAP 的 MCG_LMCE_P 没有设置,或者平台软件没有通过设置IA32_FEATURE_CONTROL.LMCE_ON (bit 20)激活LMCE,则任何尝试写或者读IA32_MCG_EXT_CTL将导致进入#GP。 这个IA32_MCG_EXT_CTL寄存器在重置时候被清除。
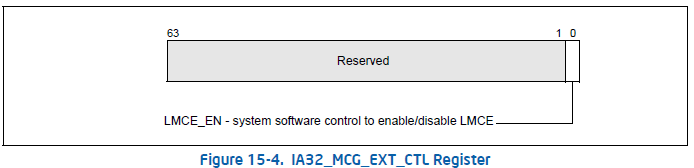
LMCE_EN (local machine check exception enable) flag, bit 0 - 系统软件设置这个位允许硬件发送MCE信号只给一个逻辑处理器。只在平台软件已经配置 IA32_FEATURE_CONTROL时候系统软件才可以设置LMCE_EN。使用LMCE需要同时配置平台软件和系统软件。平台软件可以通过设置IA32_FEATURE_CONTRL MSR(MSR地址3AH) 位20(LMCE_ON)来启用LMCE。系统软件必须确保同时 IA32_FEATURE_CONTROL.Lock(bit 0)和IA32_FEATURE_CONTROL.LMCE_ON(bit 20)在设置IA32_MCG_EXT_CTL.LMCE_EN(bit 0)之前已经设置。当系统软件激活LMCE,则硬件将检测是否有一个特别错误可以只发送给一个单一的逻辑处理器。软件不会假设何种类型错误,硬件可以选择作为LMCE发送。
MCE Bank 寄存器
更细粒度的MCE是通过MCE Bank 寄存器控制和汇报的。每个Bank至少包含IA32_MCi_CTRL,IA32_MCi_STATUS, IA32_MCi_ADDR, IA32_MCi_MISC,IA32_MCi_CTRL2寄存器。每个Bank按照它所支持的错误类型会有自己的专注领域。Bank的数量不通的处理器家族可能会一样,具体数量体现在IA32_MCG_CAP MSR(地址0179H)的[7:0]位设置。第一个错误报告寄存器(IA32_MC0_CTL)总是以地址400H开头。
-
IA32_MCi_CTL MSR控制特定硬件单元(或硬件单元组)产生错误报告。这里的64个BIT位,如果该处理器实现了该BIT,设置某个BIT位就会使对应BIT位的 MCA类型在发生时触发MCE#。

-
IA32_MCi_STATUS MSR包含了跟这个Bank相关的MCE信息如果它的VAL flag被设置起来了。软件需要写0清楚它的状态。写1回导致GP exception。

BIT15:0,BIT31:16 :这个两个部分都表示MCE的错误类型,前者是通用的,后者是跟CPU有关的;
BIT55:1表示需要软件采用Recovery Action,用于区分SRAR 和 SRAO。
BIT 57: 1表示整个处理器都被探测到的错误污染了,没法进行修复或者重新执行指令。
BIT58:1表示IA32_MCi_ADDR这个MSR是有效的,反之无效;
BIT59:1表示IA32_MCi_MISC这个MSR是有效的,反之无效;这两个BIT是因为不同MCE错误并不是都需要ADDR和MSIC这样的MSR;
BIT60:这个位于IA32_MCi_CTL中的位是对应的,那边使能了,这里就是1;
BIT61:1表示表示MCE是不可纠正的;
BIT62:1表示表示发生了二次的MCE,这个时候到底这个Bank表示的是哪一次的MCE信息,需要根据一定的规则来确定。
BIT63: 1表示 IA32_MCi_STATUS中的错误信息是有效的,系统软件正在处理。
-
IA32_MCi_ADDR MSR 当 IA32_MCi_STATUS. ADDRV = 1的时候,IA32_MCi_ADDR中含有产生本次错误的指令或数据内存的内存地址。当IA32_MCi_STATUS. ADDRV = 0,任何读写IA32_MCi_ADDR的动作都会导致#GP根据遇到的错误不同,返回的地址可能是一个段内偏移量、线性地址或物理地址。可以通过写入全0来清除该寄存器,如果在任何一位写入1都会导致#GP。

-
IA32MCi_MISC MSR 当 IA32_MCi_STATUS. MISCV = 1时, IA32_MCi_MISC MSR 中包含了本次 machine-check error的额外信息。如果IA32_MCi STATUS. MISCV = 0,任何读写IA32_MCi_MISC MSR都会导致#GP软件通过显示的写入全0来清除该寄存器,当写入任意一位1都会导致#GP如果 MISCV =1 且 IA32_MCG_CAP[24] = 1, IA32_MCi_MISC_MSR的定义如下图所示,用来支持软件恢复uncorrected errors

BIT5:0表明 error address最低有效位。 如果IA32_MCi_MISC. LSB = 01001b (9), 那么 IA32_MCi_ADDR中记录的错误地址[43:9]是有效的,[8:0]直接忽略。如果是(01100)12,那么就说明页面是4K对其的.
BIT8:6 IA32_MCi_ADDR中记录的地址的类型,支持的类型如下所示:000: segment offset 001: linear address 010: physical address 011: memory address 100/110: 保留 111: generic BIT63:9 非架构相关的
-
IA32_MCi_CTL2 MSR 提供了对于 Corrected MC Error发送信号能力的可编程接口,也同时意味着要求 IA325. _MCG_CAP[10] = 1。 系统软件检查每个Bank的 IA32_MCi_CTL2 :当 IA32_MCG_CAP[10] = 1,每Bank的 IA32_MCi_CTL2 MSR都存在。但是对于Corrected MC Error 不一定是每个bank都发送信号的,需要检查相应Bank的标志位。
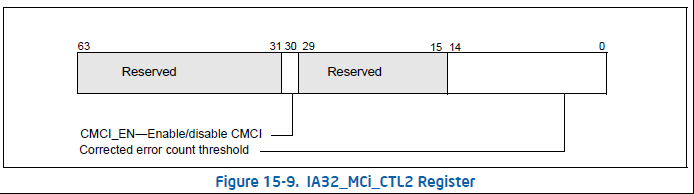
BIT14:0 系统软件负责初始化这个域,然会会同 IA32_MCi_STATUS[52:38]比较。当IA32_MCi_STATUS[52:38]等于阀值的时候, 就会发送一个 overflow事件到APIC的 CMCI LVT entry( APIC_BASE+02F0H)。如果CMCI功能没有使能,但是 IA32_MCG_CAP[10] = 1,那么这个域总是0
BIT30: 系统软件设定这个位来使能发送Corrected Machine-check Error Interrupt (CMCI) 的特性。如果某bank的CMCI没有使能,但是 IA32_MCG_CAP[10] = 1,写1到这个bit会返回0,这个BIT也就意味着对应bank的CMCI是否被支持。某些微架构作为corrected MC errors的源,肯能被多个逻辑处理器共享,那么这个bank的内容也就会被共享,软件需要负责 IA32_MCi_CTL2 MSR内容在多个逻辑处理器间的一致性问题。在系统重启后 IA32_MCi_CTL2 MSR被清零.
CMCI
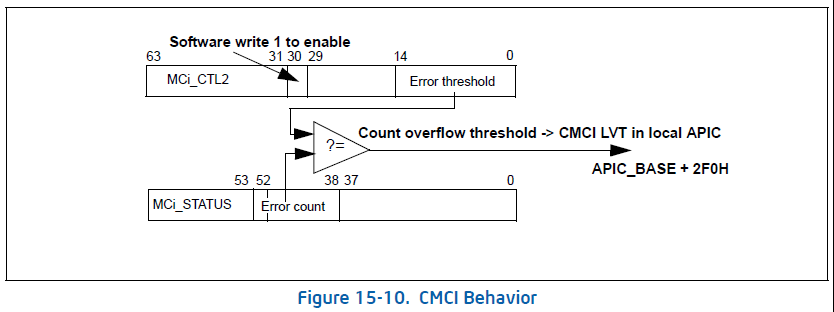
CMCI (Corrected Machine-check Error Interrupt )从45nm Intel 64 处理器(CPUID 06H_1AH)开始引入了加入到MCA的一种机制,它将错误上报的阈值操作从原始的软件轮询变成了硬件中断触发。CPU是否支持CMCI取决于IA32_MCG_CAP的BIT10。CMCI默认是关闭的,需要通过设置IA32_MCi_CTL2的BIT30来Enable,而且需要设置BIT14:0 的阈值,而且每个Bank都要单独设置。首先写1到IA32_MCi_CTL2的BIT30,再读取这个值,如果值变成了1,说明CMCI使能了,否则就是CPU不支持CMCI;之后再写阈值到BIT14:0,如果读出来的值是0,表示不支持阈值,否则就是成功设置了阈值。CMCI是通过Local ACPI来实现的,具体的示意图如下:
MCE 错误代码表
为了知道MCA汇报的错误类型,错误处理程序需要读取IA32_MCi_STATUS寄存器的error code field [15:0]。 MCA有2种类型的错误代码:简单的错误代码和复合的错误代码。

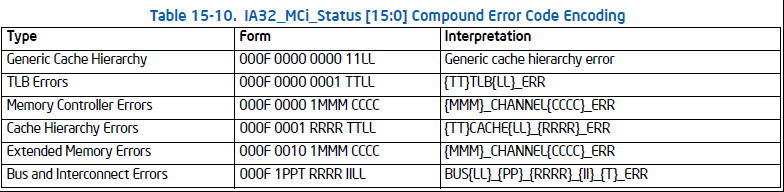


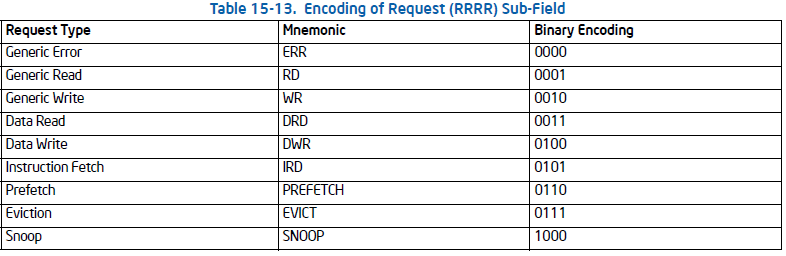
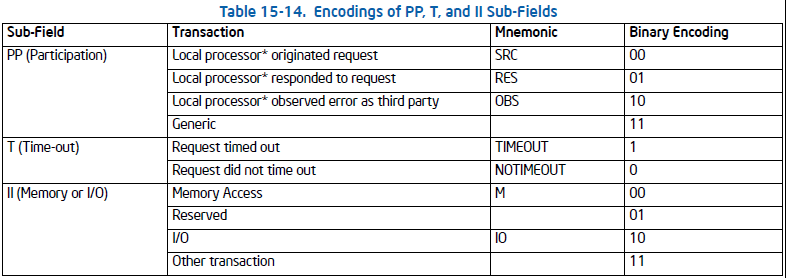
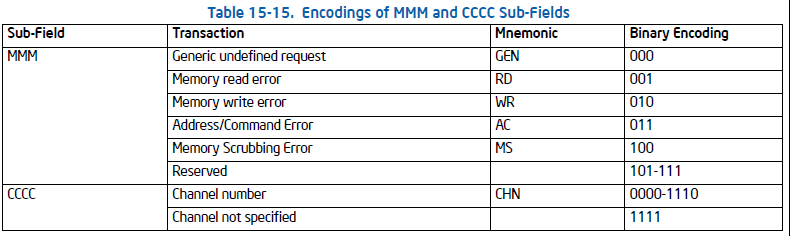
比如当我们看到一个复合型的错误代码:MC1_STATUS: 0xf200000000020151,bits[15:0]转成二进制是 0000 0001 0101 0001,依据上图compound error code encoding,我们知道这个符合(000F 0001 RRRR TTLL) 是一个cache hierarchy error,具体分析下来TT=00, LL=01, RRRR=0101,所以是一个L1 instruction fetch error,而且是一个uncorrected error。
MCE 多核实现
大多数的MCE寄存器是core相关的,每个core都有自己的Bank寄存器。但是在新的处理器系列中加入了一些新的Bank用来解决Package级别的错误信息。如有些新的处理器的Bank 0,1,6,7,他们是Package级别的主要用来处理QPI,IMC,和Graphics的MCE。而像Bank 2,3,4,5是传统的MCE Bank 主要用来解决Core级别信息如Data Cache,TLB,MLC, LLC等。
MCA 初始化

MCE UCR的恢复
UCR( uncorrected recoverable machine check errors) 错误恢复是MCA的一种增强特性,该特性允许系统软件对于特定类型的 uncorrected errors做出一些恢复性动作以便保持系统的正常稳定运行。系统软件需要通过 IA32_MCG_CAP. MCG_SER_P(bit 24)来判断是否支持软件恢复特性。当 IA32_MCG_CAP[24]被设定了,那么处理器支持软件对错误的恢复,如果被清除了,那么意味着处理器不支持软件恢复特性,UCR errors 都是硬件不可自动校正的错误( uncorrected errors), 这种错误就意味着错误被系统硬件识别到了,但是该错误还没有污染处理器的运行上下文,并且已经发送信号通知了CPU进行处理。对于特定的UCR来说,一旦系统进行了recovery的动作后(如将错误内存页进行了隔离),系统软件在处理器上就可以继续正常的执行而不会发生重启等崩溃现象。UCR error reporting提供了一种方法,通过对于数据标记错误而达到容错目的。machine check处理函数会通过寄存器读取其中的错误,然后对错误进行分析,最后根据错误的 种类来完成特定UCR的恢复动作。
根据UCR的错误类型,UCR错误可以通过CMCI方式通知,也可以通过MCE( machine check exception)方式发送。当IA32_MCG_CAP[24] = 1,通过 IA32_MCi_STATUS中的如下bit来判断是否是一个UCR: Valid (bit 63) = 1 UC (bit 61) = 1 PCC (bit 57) = 0 当 IA32_MCi_STATUS. ADDRV = 1, IA32_MCi_STATUS. MISCV = 1的时候,IA32_MCi_MISC和 IA32_MCi_ADDR中会含有与该UCR错误相关的更多信息。IA32_MCi_STATUS中的 MCA error code域标明了UCR的错误类型。系统软件通过解析 MCA error code域来分析错误类型,然后采用一些相应的错误恢复行为.另外, IA32_MCi_STATUS[56:55]提供了更多的信息来帮助系统软件更加合理的完成错误的处理。 S(Signaling)flag: bit 56 当设定后,如果该bank被报告了一个UCR,那么随之将会产生一个MCE (machine check exception),软件负责检查 IA32_MCi_STATUS中的AR标志位和MCA error code来判断到底采用哪种必要的行为来恢复错误。当 IA32_MCi_STATUS中的S位被清除,该UCR将不会通过MCE来通知,取而代之的是通过 corrected machine check (CMC)的方式报告。当没有设置S位的时候,系统软件什么都不用做。 AR(Action Required)flag:bit 55当设定后,当一个错误被通知后,系统软件必须要采取必要的恢复动作。这个动作必须在其他任务被调度到本处理器前成功完成。 当 IA32_MCG_STATUS.RIPV = 0,可以执行另外一个可选的执行流程而不必再重新执行exception前的路程。如果特定的恢复动作不能成功执行的话, 系统软件会执行关机动作。当 IA32_MCi_STATUS.AR = 0,系统还是有可能执行恢复动作,但是这不是强制的。当 IA32_MCG_STATUS. RIPV = 1,那么系统可以在执行完恢复动作后安全地重新执行栈顶的EIP指针。S和AR都被定义为粘贴位,也就是说一旦这种位被设定后,处理器就不会去清理它们。只有系统软件和 power-on reset可以清除S和AR位。和AR位只有当系统中报告了UCR错误( MCG_CAP[24] = 1)的时候才会被设置。
通过 IA32_MCi_STATUS中的S和AR两位的不同编码,可以将UCR分为如下类别:
-
Uncorrected no action required(UCNA):该类UCR不会通过MCE进行通知,而是按照 corrected machine check error的方式报告给系统软件。UCNA意味着系统都的某些数据损坏了,但是这些坏数据还没有被使用,并且处理器的状态是有效的,所以可能继续正常执行本处理器的代码。UCNA不需要系统软件做任何的动作,就可以继续执行。UCNA的 IA32_MCi_STATUS的设置为 UC = 1,PCC = 0, S = 0,AR = 0。
-
Software recoverable action optional(SRAO): 该类UCR错误会通过MCE的方式进行通知,系统可以选择不进行恢复动作也可以选择进行,不是强制的。并且不需要从发生MCE的地方继续重新执行。SRAO错误意味着系统中有错误数据,但是数据并没有被使用,处理器还是处于有效状态。SRAO提供了更多的信息让系统软件进行恢复动作。SRAO的 IA32_MCi_STATUS的设置为UC = 1,PCC = 0, S = 1,EN = 1, AR = 0。恢复的动作通过MCA error code来进行指定。如果 IA32_MCi_STATUS的 MISCV和 ADDRV被设定了,那么就可以在 IA32_MCi_MISC和 IA32_MCi_ADDR中读取到更多的错误信息。系统软件需要检查 IA32_MCi_STATUS的 MCA error code域来找到该SRAO对应的操作。如果MISCV和ADDRV没有被设置的话,建议不要进行系统恢复动作,而是继续正常执行。
-
Software recoverable action required(SRAR): 该类UCR要求系统软件在调度其他执行流到本处理器前必须执行一个恢复动作。SRAR意味着错误被发现了, 并且是在执行流程中发现并报告的错误。一个SRAR的 IA32_MCi_STATUS的设置为UC = 1,PCC = 0, S = 1,EN = 1, AR = 1。恢复的动作通过MCA error code来进行指定。如果 IA32_MCi_STATUS的 MISCV和 ADDRV被设定了,那么就可以在 IA32_MCi_MISC和 IA32_MCi_ADDR中读取到更多的错误信息。 系统软件需要检查 IA32_MCi_STATUS的 MCA error code域来找到该SRAR对应的操作并执行它。如果MISCV和ADDRV没有被设置的话,建议直接采用关机处理.
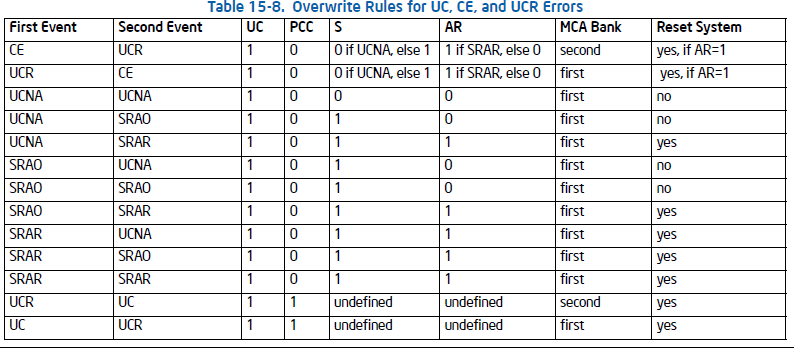
UCR errors、 Corrected errors 和 Uncorrected errors分类如下:
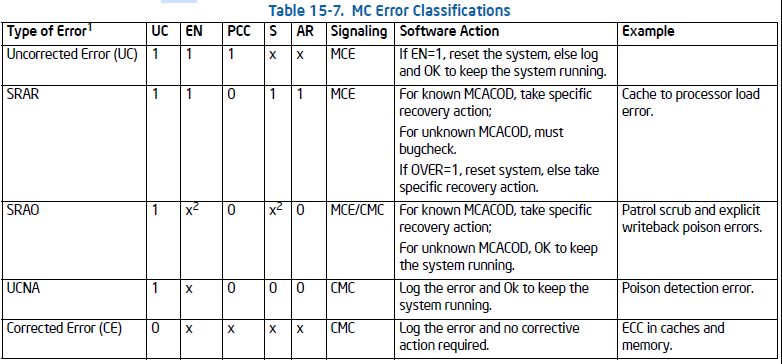
另外,关于覆写规则一般如下
-
UCR 覆盖 corrected errors
-
Uncorrected (PCC=1) errors 覆盖 UCR (PCC=0) errors.
-
UCR errors 不会覆盖前一个 UCR errors
-
UCR errors 不会覆盖前一个 UCR errors
IA32_MCi_STATUS.OVER 来标记是否有覆盖的情况发生。注意如果OVER的情况,且AR或PPC被设置了,那么就需要重启系统。
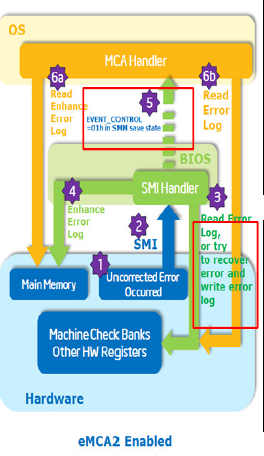
EMCA2 FFM 错误处理流程
EMCA2 Overview
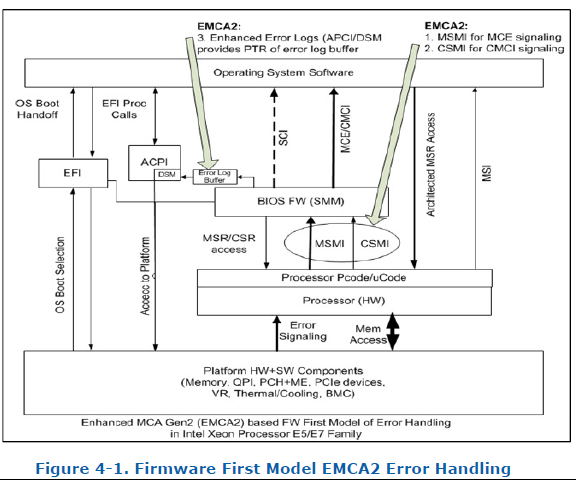
EMCA2(Enhanced Machine Check Architecture Gen2)是在Intel Xeon 处理器E7-v3引入的。它是用来将MCE和CMCI转成SMI先发给BIOS去处理然后再交给OS 处理的一个RAS feature。它实现了基于BIOS的错误恢复机制。EMCA使得BIOS能够先处理,它可以访问MSR,CSR的错误日志寄存器,收集并产生ehanced error logs然后汇报给系统软件,通过这种方式系统软件能够获得更加丰富的错误信息为更深入的错误恢复策略提供支持。
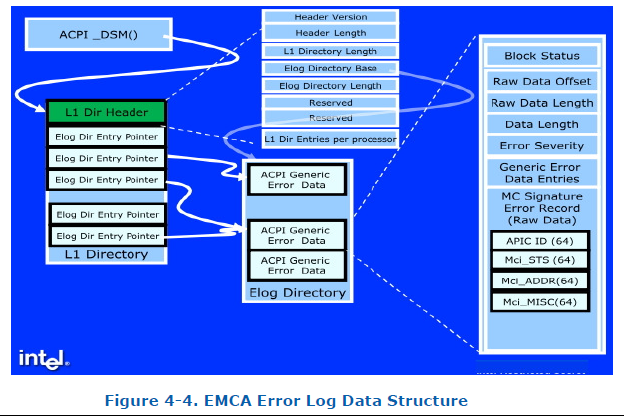
Enhanced MCA Log 数据格式
Bit 26 of IA32 MCG_CAP MSR 表示这个处理器是否支持Enhanced MCA Logging,BIOS 通过ACPI _DSM method 通知OS Function 0 表示是否支持这个feature,Function 1返回该数据格式的地址。

Enhanced MCA L1 Directory, 首先包含的是一个Header(包含Elog Dir base,length),跟在Header后面就是Error Log Directory data structures,每一个Entry对应一个Bank。Error Log Directory是一个连续的数据结构,都包含了一个ACPI Generic Error Data structure
参考:
machine-check-exceptions-debug-paper
Intel® 64 and IA-32 Architectures Software Developer’s Manual
emca2-integration-validation-guide-556978
MCA机制:硬件错误检测架构: https://blog.csdn.net/chengm8/article/details/53003134
x86架构——MCA: https://blog.csdn.net/jiangwei0512/article/details/62456226#comments_13770151